Transformer 的训练与推理
本文是对 Transformer 训练和预测过程的一些细节理解记录, 基于 The Illustrated Transformer, 本文内符号也沿用此文.
主要是对于 Decoder 部分训练和预测时的区别以及并行化原理的总结.
数据流动回顾
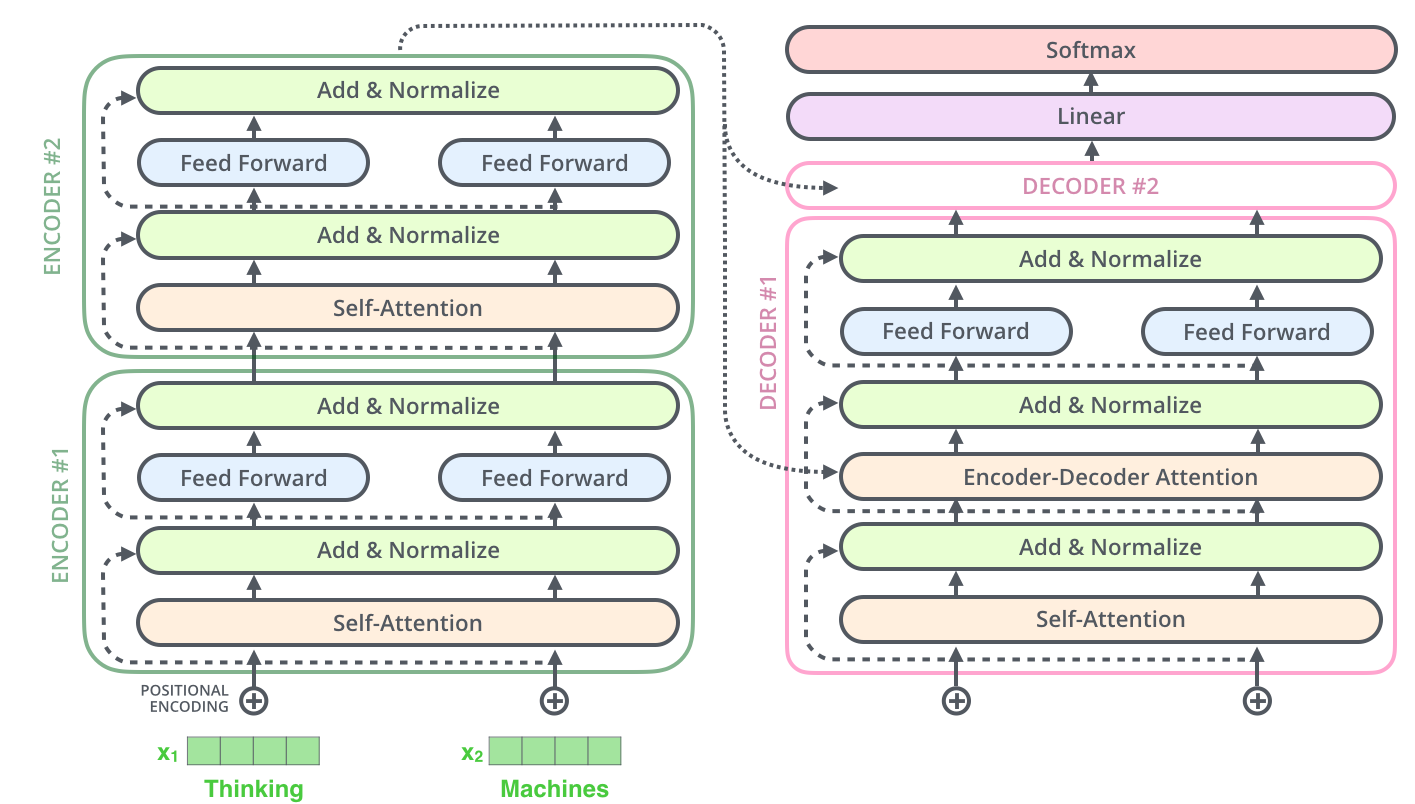
这张图是一个简略的 Transformer 整体框架图.
对于 Encoder 部分, 输入是 (B, T, E) 的形状, 其中 B 是批大小, T 是最大句长, E 是词向量长度; 输出形状和输入相同, 也是 (B, T, E), 并且这同一份数据对应接下来 Decoder 其中一层注意力的 Key 和 Value 输入.
而对于 Decoder 部分, 同样设输入形状是 (B, T, E), 那么它的输出形状也是和输入形状一样为 (B, T, E).
最后的 Liner 和 Softmax 则是将 Decoder 的 (B, T, E) 映射到词典大小的概率矩阵 (B, T, vocab_size).
训练过程
Encoder 部分很简单, 在训练和预测上没有什么理解上的问题, 主要是 Decoder 部分是如何做到并行化的.
前面说到, 对于 Decoder 而言, 输入和输出的形状都是一样的 (B, T, E), 那么首先要知道的是, 此处的并行化, 是在训练时将不同时间步的输出并行化了.
对于 t 个时间步的输入 $[x_0, x_1, \ldots, x_{t-1}]$, Decoder 的输出是 $[y_1, y_2, \ldots, y_t]$, 而它们的对应关系如下所示:
$$
\begin{bmatrix}
x_0 & ~ & ~ & ~ \\
x_0 & x_1 & ~ & ~ \\
\vdots & \vdots & \ddots & \vdots \\
x_0 & x_1 & \ldots & x_{t-1}
\end{bmatrix} \Rightarrow \begin{bmatrix}
y_1 \\
y_2 \\
\vdots \\
y_t
\end{bmatrix}
$$
而实现这种并行的关键是 Masked-Attension, 这个网上有很多举例, 简单来说就是对于 $y_i$, 通过 Mask 让它只包含了 $[x_0, x_1, \ldots, x_{i-1}]$ 的信息.
最后把这 t 个时刻的不同长度的输入序列 "叠" 在一起, 得到了等长的依次排在一起的不同时刻的输出.
预测过程
通过前面的训练过程可以知道, 从原理上来说, 虽然 Decoder 的输入和输出形状相同, 但是每个时间步的输入序列只有一个输出符号, 也就是预测出来的下一个输入符号, 因此 Decoder 在预测时, 是串行的循环过程, 直到出现终止符.

那么来看这张图, 预测时, Decoder 一开始的输入 (B, T, E) 里面, 只有第一个符号是有效的, 并且是开始符, 随后进行预测, 得到了输出数据 (B, T, E), 但是只需要取输出的第一个符号, 并且也只有这个符号有效, 它将作为下一个要拼在输入序列后面的第二个符号.
随后重复上述步骤, 对于 t 时刻的操作, 输入的 (B, T, E) 内只有前 t 个符号有效, 而得到输出序列 (B, T, E) 后也只有前 t 个符号有效, 并且第 t 个符号就是下一个要接在输入序列后的预测符号, 而前 t - 1 个符号可以忽略不要, 因为它就是之前已经使用过的已经放在输入序列里的符号 (因为第 i 个输出符号只受前 i - 1 个输入符号的影响, 因此输入序列变长也不影响曾经的输出符号结果, 只有最后的第 t 个输出符号是新内容).
循环整个过程, 直到遇见终止符, 就可以解码出完整的预测结果.
参考
- The Illustrated Transformer